





В марте 2026 года Андрей Карпаты публично заявил, что не написал ни одной строки кода с декабря 2025-го. Не потому что ушёл из индустрии - наоборот, он продолжает строить и запускать продукты. Просто весь код за него теперь пишут ИИ-агенты. Сам он перешёл в роль менеджера (оркестратора): формулирует задачу, задаёт критерии, проверяет результат.
Если бы о таких достижениях написал кто-то из инфоцыган, можно было бы смело пройти мимо. Однако, Карпаты это один из самых уважаемых людей в индустрии AI, человек-легенда, который стоял у истоков ChatGPT и Tesla Autopilot. Когда он говорит о фазовом сдвиге в разработке, к нему стоит прислушиваться.
В этой статье мы с вами разберемся в основных принципах работы с ИИ-агентами, которые предлагает этот гуру из кремниевой долины.
Кто такой Андрей Карпаты и почему к его мнению стоит прислушиваться

Если вы совсем недавно начали погружаться в ИИшный движ, то его имя может вам ничего не говорить. Но в индустрии AI это фигура уровня условного Стива Возняка для эпохи нейросетей.

Параллельно с этим Карпаты является публичным преподавателем. Его курс Neural Networks: Zero to Hero на YouTube посмотрели миллионы. Его эссе Software 2.0 (2017 год) стало классикой, там он за пять лет до бума объяснил, почему программирование начнёт сдвигаться от написания инструкций к обучению моделей.
Его открытые проекты: nanoGPT, micrograd и LLM.c стали учебниками для целого поколения инженеров машинного обучения.
Почему всё это важно для нашей темы? Потому что Карпаты это редкий случай человека, который одновременно:
- Строил ИИ в масштабе Tesla, OpenAI
- Преподаёт и умеет объяснять сложные вещи простым языком
- Видит индустрию глобально с высоты "птичьего полета"
Когда такой человек публикует список наблюдений типа: «вот тут модели лажают, вот так это лечится», это не очередной пост ради контента.
Это выжимка ценного опыта, на которую сообщество молниеносно реагирует, буквально за недели вокруг его постов вырос репозиторий на Github forrestchang/andrej-karpathy-skills, который собрал 45 тысяч звёзд.
Можно сказать, что это отраслевой стандарт того, как настраивать поведение Claude Code и других ИИ-агентов.
Фазовый сдвиг в конце 2025 года
Сначала немного контекста, чтобы было понятно, о каком сдвиге речь.
До декабря 2025-го вайбкодинг и ИИ-агенты выглядели не серьезно, чисто поиграться и сделать пару простеньких ботов или скриптов. Как только задача требовала пройти десять шагов подряд, удержать контекст, прочитать логи, поправить код, перезапустить, проверить - они сразу терялись и начинали ломать то что строили. Разработчики использовали их как ассистентов, не более: подсказать строчку, подсказать функцию и т.д.
С декабря 2025-го все изменилось. Карпаты называет это пересечением порога связности, то есть способности агента удерживать длинную цепочку шагов без потери контекста.
Claude Code, Codex и аналогичные инструменты внезапно научились крутиться в одном цикле часами, не теряя нить. Можно поставить задачу на ночь и утром получить готовый, рабочий код.
Что значит "ИИ-агент" в данном контексте. Простая нейронка (например, ChatGPT в браузере) — это «отвечалка»: вы даёте текст, он даёт ответ. ИИ-агент — это нейронка, которыая умеет действовать: запускать команды в терминале, читать и редактировать файлы, вызывать API, проверять результат и решать, что делать дальше. Claude Code — это интерфейс, в котором Claude получает доступ к вашему компьютеру и может работать как разработчик: открывать проект, писать тесты, запускать их, видеть ошибки, чинить. Подробнее об отличиях нейронок и агентов смотрите в нашем видеогайде.
Со слов Карпаты это привело к полному перевороту его раочих процессов. Раньше он писал 80% кода руками с автокомплитом, а 20% делегировал. Теперь 80% делает агент, а 20% это ручные правки. К марту 2026-го пропорция дошла до того, что он перестал писать код вообще! Это и есть тот самый фазовый сдвиг.
Что такое вайбкодинг
Термин Vibe Coding придумал и ввёл сам Андрей Карпаты, еще в начале 2025 года. Идея оказалось настолько простой, что большинство даже не восприняли это всерьез.
В классическом подходе разработчик пишет код. Каждая строка это его ручная работа. Код это актив: его проектируют, ревьюят, поддерживают годами, оптимизируют.
В вайбкодинге разработчик просто описывает задачу, добавляя, что хочет видеть и как это должно работать. ИИ-агент сам составляет план действий, все изучает и пишет код, проверяет, дописывает, пока цель не будет достигнута.
Код перестаёт быть активом - он становится расходником. Сгенерировал, использовал, выбросил. Одноразовые сайты и программы, по 5-10 обновлений проекта за один день. Всё это уже реальность.
Карпаты приводит конкретный пример: он может за вечер навайбкодить целое отдельное приложение только для того, чтобы найти один баг в основной системе. Раньше никто бы такое не стал делать, это уйма свободных человека-часов, если писать руками. Теперь, почему бы и нет.
Что это дает на практике?
Вы можете генерировать маленькие, одноразовые фичи под свои задачи. Например: маленький скрипт, который проверит, что у вас в данных не так. Простая страничка, которая покажет ваши цифры в виде графика. Генератор ненастоящих данных, чтобы потестить идею. Крошечная утилита, которая нужна вам ровно на сегодня.
Раньше такое делать было лень, полчаса возни ради пятиминутной задачи. Люди просто держали всё в голове или мучались, вглядываясь в сухой текст в консоли. Теперь агент напишет вам такой одноразовый инструмент за пару минут.
Это и есть новая суперсила: маленькие программы стали почти бесплатными и кто это понял, теперь работает в разы эффективнее остальных, потому что перестаёт себя ограничивать.
Однако критически важно понимать, что вайбкодинг это не панацея. Если бездумно закинуть ИИ-агенту все идеи и задачи в один промпт и пойти пить кофе в ожидании чуда. Скорее всего агент справится, но качество этого кода будет хромать.
И тут мы переходим к главному...
Четыре проблемы нейронок, которые можно порешать правилами
Карпаты прямо перечисляет, на чём ИИ-агенты системно лажают:

Если вы хоть раз пытались вайбкодить с Claude или Codex, то скорее всего что-то из этого вам уже знакомо.
Что предлагает Карпаты
Не пытаться править модель уговорами в каждом промпте, а один раз положить в проект файл с правилами, который агент будет читать перед каждым действием.
В Claude Code этот файл называется Сlaude.md и кладётся в корень репозитория (папки). В Codex - аналогично. Содержимое файла - это четыре принципа, которые точечно закрывают все четыре провала.
Что такое CLAUDE.md технически. Это обычный текстовый файл в формате Markdown в корне вашего проекта. Claude Code при запуске автоматически его подгружает в контекст и обращается с его содержимым как с инструкциями от вас. То есть всё, что вы туда положите, действует на все ваши задачи в этом проекте и не нужно повторять всё в каждом промпте.
И вот здесь мы подошли к самой мякотке...
Решение
Принцип 1: Думай, прежде чем писать код (Think Before Coding)
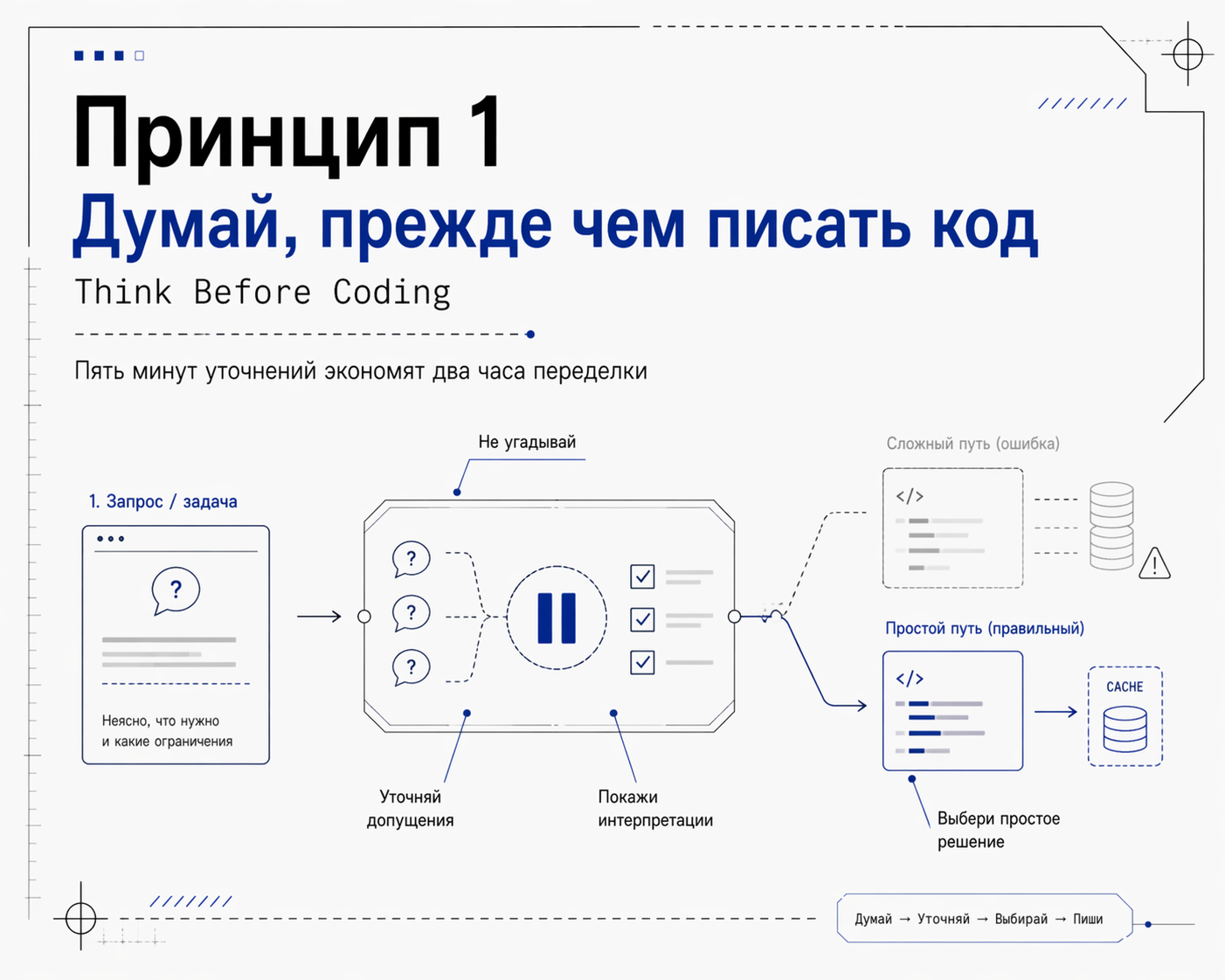
Главная беда LLM (больших языковых моделей) в том, что они обучены все знать и выглядеть уверенно. Модель почти никогда вам не скажет «я не знаю», даже если действительно не знает.
Это побочный эффект от обучения "быть полезной". При написании кода это выливается в то, что модель втихую может выбрать одну из возможных интерпретаций задачи и побежит ее выполнять.
Что должно быть в правилах:
- Явно проговаривать допущения. Если что-то непонятно - спросить, а не угадывать
- Если запрос двусмысленный - показать все интерпретации и спросить, какая нужна.
- Возражать, если видит более простое решение. Не соглашаться со всем молча.
- Останавливаться при путанице. Назвать, что именно не понятно.
Например, вы просите ии-агента: «сделай, чтобы эта страница моего сайта открывалась быстрее». По сути вы просите добавить кеширование это когда результат запоминается, чтобы не пересчитывать его каждый раз заново (как закладка в браузере, только внутри программы).
Агент без правил услышал слово и помчался: подключает отдельную серверную базу для кеша, настраивает, сколько времени данные должны жить, придумывает, как их там раскладывать и как потом обновлять. Через 20 минут у вас 500 строк сложной инфраструктуры, которая, возможно, вообще не нужна. Может, страницу просто нужно было положить в память на пять минут, и всё.
Агент с правилом «Think Before Coding» остановится и спросит:
- Кеш на уровне приложения (in-memory) или внешний (Redis, Memcached)?
- Какая политика инвалидации, по TTL или явная?
- Нужен ли распределённый кеш, если у вас несколько инстансов?
- Может, достаточно HTTP-заголовков Cache-Control на уровне Nginx?
Это ровно та интеллектуальная пауза, которой обычно не хватает. Пять минут уточнений экономят два часа переделки.
Когда модель начинает задавать уточняющие вопросы, новички часто отмахиваются: «да делай как считаешь нужным, мне всё равно». Это убивает весь смысл правила. Если вам действительно всё равно, тогда модель угадает не то и придётся переделывать. Лучше потратить минуту и ответить на вопросы. Возможно придется задавать уточняющие вопросы для себя - это нормально.
Принцип 2: Сначала простота (Simplicity First)
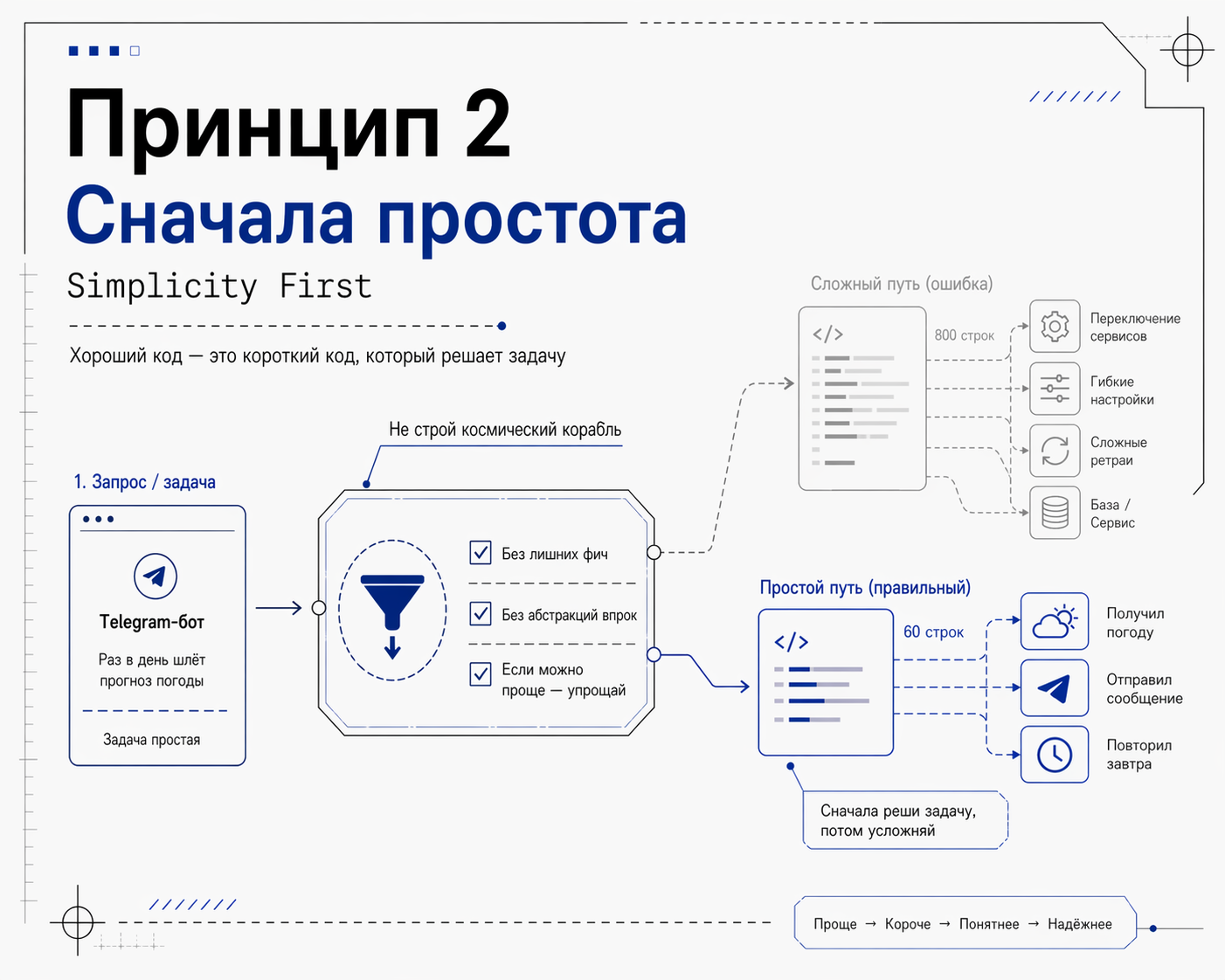
Это прямой удар по главной болезни LLM - склонности делать из мухи слона. Там, где задача решается в три строчки, модель норовит построить космический корабль с запасом прочности на все случаи жизни.
Почему модели так любят раздувать код? Потому что они обучены на миллионах репозиториев из GitHub, где архитекторы любят абстракции, паттерны, фабрики, DI-контейнеры. Модель статистически воспроизводит то, что чаще видела. А чаще она видела правильный энтерпрайз-код (Enterprise), а не короткие практичные решения.
В результате на запрос «посчитай сумму чисел в массиве» вы можете получить класс SumCalculator с интерфейсом ICalculable, абстрактной фабрикой и обработкой шести экзотических ошибок.
Что должно быть в правилах:
- Никаких фич сверх того, что попросили
- Никаких абстракций для одноразового кода
- Никакой гибкости и конфигурируемости, которую не запрашивали
- Никакой обработки ошибок для невозможных сценариев
- Если 200 строк можно уложить в 50, значит надо уложить
Тест старшего разработчика: прежде чем принять код, мысленно покажите его разработчику, у которого мало времени и плохое настроение. Если в ответ услышите «зачем тут это, зачем тут вот это, можно проще» — значит, действительно надо проще.
Например, вы просите ИИ-агента: «сделай Telegram-бота, который раз в день шлёт прогноз погоды».
Без правила: агент решает подстраховаться на все случаи жизни. А вдруг вы захотите поменять сервис погоды. Давайте сделаем так, чтобы можно было легко переключаться между разными. А вдруг понадобится показывать погоду в пяти разных видах, добавим гибкие настройки. А вдруг сервер погоды ляжет, напишем сложную систему повторных попыток. В итоге 800 строк кода, в которых сам чёрт ногу сломит.
С правилом: агент пишет 60 строк. Спросил погоду, отправил сообщение в Telegram, раз в день повторил. Работает. Если когда-нибудь реально понадобится что-то поменять, поправите пять строк, не страшно. Разница в 13 раз по объёму и легче разобраться в будущем.
Хороший код — это короткий код, который решает задачу.
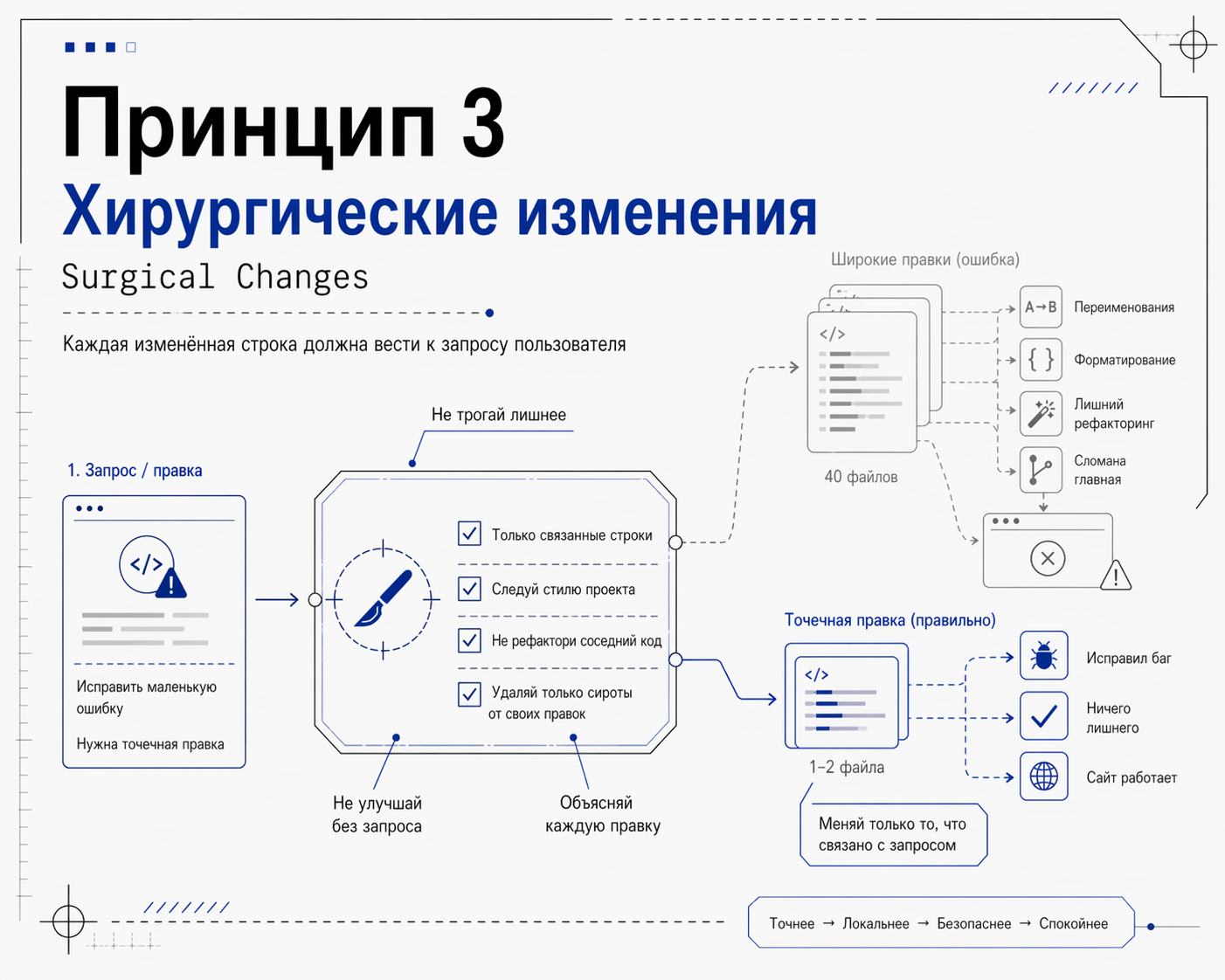
Принцип 3: Хирургические изменения (Surgical Changes)
Этот принцип решает одну из самых бесящих проблем повседневной работы с агентами. Вы просите поправить одну маленькую ошибку, а в результате агент перелопатил 40 файлов в вашем проекте.
Попутно "навёл порядок" везде, до чего дотянулся: переименовал переменные для большей ясности, поправил отступы, переписал ваши комментарии, заодно улучшил соседний кусок кода, который работал и без него.
Проблема в том, что половина этих улучшений действительно полезные, а половина, явно что-то ломает. И вы потом два часа сидите и разбираетесь: что именно сломалось, где и почему раньше работало, а теперь нет.
Что должно быть в правилах при редактировании существующего кода:
- Не улучшать соседний код, комментарии, форматирование
- Не рефакторить то, что не сломано
- Следовать существующему стилю кода, даже если он модели не нравится. Если в вашем проекте весь код написан в одной манере, значит, новый кусок кода должен быть в той же манере, а не в той, которую модель считает более правильной. Единообразие важнее личных вкусов
- Если замечен мёртвый код, обязательно упомянуть, но не удалять без явного запроса
Когда твои изменения порождают «сирот» (неиспользуемые импорты, переменные, функции):
- Удалить то, что стало ненужным из-за твоих изменений
- Не удалять мёртвый код, который был там до тебя. Может, он нужен для миграций, тестов или кода в другой ветке
Каждая изменённая строка должна однозначно вести к запросу пользователя. Не можете объяснить, зачем вы это поменяли, значит, не надо было трогать.
Это критично для бизнеса. Если вы пилите что-то для себя, тогда лишние правки агента просто раздражают. Но если это рабочий продукт, которым пользуются клиенты, всё меняется.
Представьте: вы попросили агента добавить маленькую фичу на сайт. Он попутно «улучшил» ещё пару мест и внезапно у ваших пользователей перестаёт открываться главная страница. В пятницу вечером. Час работы превращается в сутки аврала: звонки, извинения, ушедшие клиенты, просевшая выручка. Одно «невинное улучшение» и вы весь уикенд тушите пожар вместо отдыха.
Принцип 4: Исполнение через цели (Goal-Driven Execution)
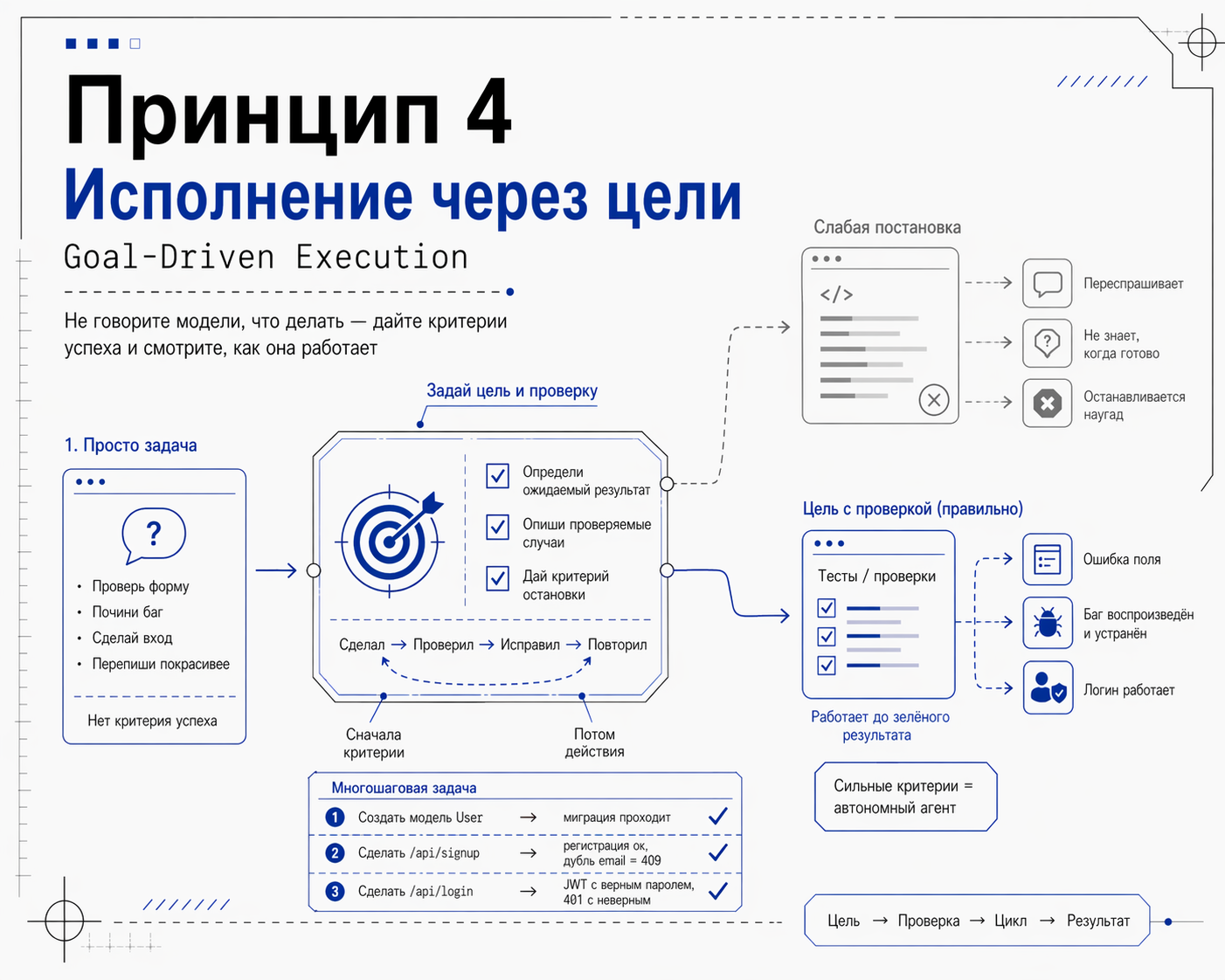
Это ключевой принцип. Карпаты считает его главным. Цитата:
«Большие языковые модели (LLM) исключительно хороши в том, чтобы крутиться в цикле до достижения конкретных целей. Не говорите модели, что делать - дайте ей критерии успеха и смотрите, как она работает».
Суть принципа: не просите агента "сделай это", лучше просите "должно получиться вот так, и вот как это проверить".
Разница между этими двумя подходами огромна:
| Просто задача | Задача с чёткой целью |
|---|---|
| «Проверяй, что пользователь ввёл правильные данные в форму» | «Если поле пустое — покажи ошибку „заполните поле“. Если в поле „возраст“ написано слово, а не число — покажи ошибку „введите число“. Проверь, что все эти случаи обрабатываются» |
| «Почини баг — сайт иногда зависает» | «Найди, в какой именно ситуации сайт зависает. Повтори эту ситуацию. Теперь сделай так, чтобы в этой же ситуации всё работало» |
| «Перепиши этот кусок кода покрасивее» | «Сначала проверь, что сейчас всё работает. Перепиши. Проверь, что после переписывания всё работает точно так же» |
| «Сделай вход в личный кабинет» | «Пользователь вводит почту и пароль — попадает в личный кабинет. Если пароль неверный — видит сообщение „неверный пароль“. Если почты вообще нет в базе — видит „пользователь не найден“. Проверь оба варианта, потом делай» |
Чувствуете разницу? Где есть логическая подоплёка и где ее нет?!
Что значит крутиться в цикле. Когда у агента есть критерий проверки (например, все тесты должны быть зелёными), он может работать сам: попробовать решение, запустить тесты, увидеть, какие красные, поправить, перезапустить и так пока не получится. Без вашего участия. Это как доверенный младший разработчик, который сам понимает, когда задача готова. Без чёткого критерия модель не знает, когда остановиться и постоянно дёргает вас.
Для многошаговых задач формулируйте план с проверками на каждом шаге:
1. Создать модель User с полями email, password_hash, created_at
→ проверка: миграция применяется без ошибок
2. Реализовать регистрацию /api/signup
→ проверка: тест на успешную регистрацию проходит,
тест на дубль email возвращает 409
3. Реализовать вход /api/login
→ проверка: с правильным паролем возвращает JWT,
с неправильным — 401
И это вовсе не лишняя дроч (я тоже так работаю). Это рычаг производительности: чем чётче критерии и логика, тем меньше вы нужны в процессе.
Сильные критерии = автономный агент. Слабые (сделай, чтобы работало) = постоянное переспрашивание.
Разработчики, знакомые с Test-Driven Development, узнают подход: сначала тест, потом код. Именно эта парадигма идеально ложится на работу с ИИ-агентами. Если раньше TDD был модной практикой для дисциплинированных, то теперь это просто самый эффективный способ выдавать задачи ии-агентам. Тест = объективный критерий успеха.
Бонусные наблюдения Карпаты
(за рамками четырёх принципов)
Четыре принципа это ядро, но у Карпаты есть ещё несколько козырей в рукаве, которые меняют сам подход к работе с ИИ-агентами. Они не попали в формальный CLAUDE.md, но без них картина была бы не полной.
Диверсифицированный рабочий процесс
Карпаты не использует один инструмент на всё - это важно. Однако, если вы новичок, то настоятельно рекомендую разобраться в чем то одном.
Его основной рабочий инструмент tab completion в Cursor, около 75% всего LLM-ассистирования. Cursor это редактор кода (форк VS Code) с интегрированными ИИ-агентами. Tab completion это когда вы начинаете писать строку кода, а редактор предлагает её дописать.
Почему 75%? Потому что когда вы сами пишете начало кода или комментарий в нужной точке файла, вы максимально плотно передаёте модели контекст.
То есть вы буквально показываете: вот окружение, вот моё намерение, достраивай. Это самый дешёвый и точный способ направить модель.
Агенты идут сверху для больших задач, где нужно связать несколько файлов, запустить код, прочитать логи, поправить, перезапустить. Точечные правки остаются за tab completion. Архитектурные обсуждения за чатом с агентом.
Не ищите один волшебный инструмент. Разные слои задачи требуют разных подходов:
- Точечная правка → tab completion в редакторе
- Объяснение концепции, обсуждение подхода → чат с моделью
- Большая многошаговая задача → агент (Claude Code, Codex)
- Поиск по своим заметкам → Claude Code по вашей LLM Wiki
LLM Wiki - личная база знаний в markdown формате
Наверняка у вас накопились сотни статей в закладках, десятки PDF-ок, заметки из чатов с ChatGPT и Claude — и вы каждый раз не можете найти ту самую мысль, которую точно где-то видели месяц назад. Знание копится, но не работает.
Карпаты в своём апрельском gist'е (за неделю собравшем 5000+ звёзд на GitHub) описал простое решение: держите все заметки, статьи и конспекты как обычные текстовые файлы в одной папке на компьютере — и натравите на неё ИИ-агента. Он сам читает, сам ищет, сам отвечает — но уже на основе ваших знаний, а не случайных статей из интернета.
Никаких Notion, Obsidian с тридцатью плагинами и подписок — просто папка и агент. Вы владеете всем, можете версионировать через git, ничего не теряется.
Это и есть «вторая память» — только реально работающая.
Подробный разбор этого подхода с пошаговой настройкой, смотрите в нашем недавнем видеогайде. Там я показал всё на своём примере: как организовать папки, как подключить агента, как превратить хаос из закладок в живую систему, которая сама наполняется и сама отвечает.
Локальный дух в компьютере
Карпаты считает, что Claude Code это первая по-настоящему убедительная демонстрация ИИ-агента. Главное преимущество в том, что он работает на вашей машине, с вашими данными, в вашем приватном окружении.
Облачные контейнеры, на которые делает ставку часть индустрии (например, OpenAI с их Codex Cloud) это, по мнению Карпаты, шаг не туда.
Когда агент работает в облаке, у вас нет доступа к локальным конфигам, секретам, базам, файлам. Каждый раз нужно что-то прокидывать, копировать, синхронизировать... сплошной мрак и неудобства.
Когда агент работает локально, он видит ваше окружение целиком. Может прочитать ваш конфиг VPN, поправить что-то в системе, заглянуть в локальный SQLite, проверить свой код в вашем Docker. Это на порядок круче и мощнее.
Для тех, кто работает с инфраструктурой, приватными данными или просто ценит контроль это огромный плюс.
Что остаётся за человеком
Вы могли слышать фразочки типа: «всё, агенты заменят программистов, мы не нужны».
Однако Карпаты на спокойных щах заявляет, что не заменят. Но то, чем придётся заниматься человеку изменится на корню. За вами остаются четыре вещи, которые агент не сделает:
- Решить, что вообще делаем. Агент не знает, какую задачу вам нужно решить в жизни. Это решаете вы
- Объяснить, что именно нужно. Чем яснее вы опишете результат, тем лучше он сработает. Мутный запрос = мутный ответ
- Проверить, что получилось. Агент напишет и скажет готово. А работает ли оно на самом деле, проверяете вы
- Подумать, туда ли мы вообще идём. Может, задачу вообще не надо решать. Может, есть путь проще. Это чисто человеческая работа
Модель она как шустрый всезнайка, но не надёжный. Разработчик перестаёт быть исполнителем и становится дирижёром и ревьюером.
Это другая профессия, и в ней выигрывают не самые быстрые наборщики, а те, кто умеет думать системно и точно формулировать логики.
Если вы только заходите в эту область, учитесь не быстро писать, а ясно думать и точно ставить задачи. Это и есть новая ключевая компетенция.
Как все это применять в своих рабочих процессах?
Шаг 1. Поставьте Claude Code
Если ещё не пользовались, того пора начинать. Установите Claude Code. Он работает на macOS, Linux и Windows (через WSL). Привязывается к вашей подписке Claude.
Более подробные гайды по работе с Claude, Codex, агентами и прочим, ищите в нашей специальной ветке AI и ИИ - ТЫК
Шаг 2. Положите CLAUDE.md в проект
Самый простой способ, взять готовый файл из репозитория и положить в корень проекта одной командой:
curl -o CLAUDE.md https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md
Если у вас уже есть свой CLAUDE.md — допишите карпатовский снизу:
echo "" >> CLAUDE.md
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
Claude Code автоматически подхватит файл и будет следовать правилам.
Шаг 3. Допишите свои проектные правила
Под четырьмя принципами Карпаты можно дописать специфику вашего проекта:
## Project-Specific Guidelines
- Используем Python 3.12, типизация обязательна (mypy strict)
- HTTP — только httpx, не requests
- Тесты — pytest, в папке tests/
- Логирование — structlog, формат JSON
- Все API-эндпоинты должны иметь тесты на happy path и хотя бы один error case
- Следовать существующим паттернам обработки ошибок в src/utils/errors.py
Чем точнее вы опишете контекст проекта, тем меньше модель будет угадывать.
Оригинальный шаблон можно найти здесь: https://github.com/forrestchang/andrej-karpathy-skills/blob/main/.cursor/rules/karpathy-guidelines.mdc
Шаг 4. Проверьте, что правила работают
Признаки того, что всё настроено правильно:
- Появляются только запрошенные изменения, не больше
- Код простой с первого раза, не приходится переписывать из-за перегрузки
- Уточняющие вопросы агент задаёт до реализации, а не после ошибки
- Pull request-ы чистые, без случайных улучшений соседнего кода
Если этого не наблюдается, значит, агент игнорирует CLAUDE.md (бывает редко) или правила слишком общие. Уточните формулировки.
Важный нюанс
Эти правила смещают баланс в сторону осторожности, а не скорости. Для тривиальных задач (опечатка, однострочник) полный набор может тормозить, модель будет переспрашивать там, где не надо - имейте ввиду.
Подведём итоги
Вот вы и дочитали. Теперь дело за малым - применить. Если вы только заходите в мир нейронок, то не пытайтесь сразу освоить всё, начните с азов: поставьте Claude Code, поиграйтесь с простыми задачами, почувствуйте, как агент реагирует на разные формулировки.
Если вы уже в теме и давно кодите с ИИ, пробуйте внедрять эти четыре принципа в свой рабочий процесс по одному. Не сразу всё, иначе ничего не приживётся. Начните с Goal-Driven Execution, это даст самый заметный эффект уже на первой неделе.
Мир действительно меняется на глазах. То, что ещё пару лет назад требовало команды разработчиков, бюджета и месяцев работы, сегодня может сделать один человек за выходные, если он умеет правильно разговаривать с агентом.
Свой Telegram-бот, сервис, мини-SaaS, лендинг с автоматизацией — всё это теперь в пределах досягаемости каждого, у кого есть идея и немного усидчивости.
А там, где появляется продукт, появляются и деньги. Порог входа в предпринимательство никогда не был таким низким. Вопрос только в том, воспользуетесь ли вы этим окном или будете смотреть, как это делают другие.